Seventeen active AI pilots. $2.3 million in annual spend. Zero measurable business outcomes. That was the state of AI at a mid-market professional services firm when their CFO finally asked the question everyone had been avoiding: “Which of these should we actually scale?”
Nobody could answer. Not because the pilots weren’t working — several were. But none had been designed to produce the data needed to make a scaling decision. They were experiments without exit criteria, running indefinitely on the premise that “we’ll figure out ROI later.” Later never came.
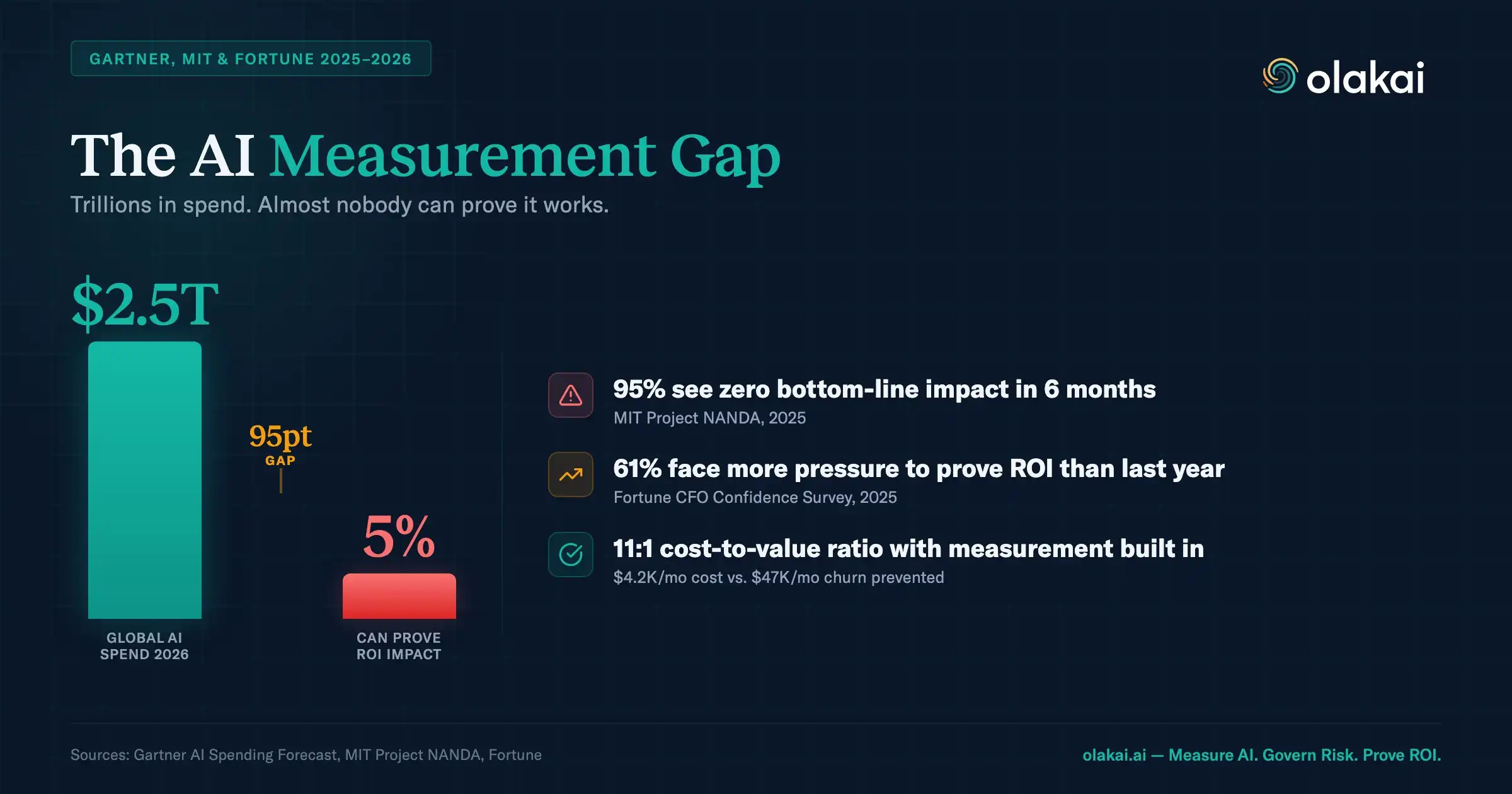
This is pilot purgatory — and MIT’s 2025 State of AI research found that 95% of enterprise AI pilots deliver zero measurable financial return. Not low returns. Zero. That’s roughly $30-40 billion in destroyed shareholder value from AI pilots running worldwide without the measurement infrastructure to prove they’re worth continuing.
The Pilot Purgatory Problem
The data on AI pilot failure is stark. S&P Global Market Intelligence found that the average enterprise scrapped 46% of AI pilots before they ever reached production in 2025. Bain’s executive survey reported that only 27% of companies successfully moved generative AI from testing to real-world implementation. And McKinsey’s State of AI report found that nearly two-thirds of organizations remain stuck in pilot phase, unable to scale projects across the enterprise despite significant adoption.
The financial toll is substantial. Industry analysis estimates that pilot purgatory costs the average enterprise $15-25 million annually in wasted development resources, infrastructure spending, and opportunity costs. Individual pilot failures run $500,000 to $2 million each. And the cost grows every month a pilot runs without producing decision-quality data, because the organization continues investing without the information needed to decide whether that investment is justified.
The root cause isn’t technical. Most AI pilots work from a technical standpoint — the models perform, the integrations function, the users adopt the tools. The root cause is that pilots are designed to test technology, not prove business value. They answer “can this AI tool do the thing?” when the question the organization needs answered is “should we invest more in this AI tool?”
Why 30 Days Is the Right Timeframe
Enterprise best practice points to a 30-to-45-day window as the optimal pilot duration. Short enough to maintain executive attention and organizational momentum. Long enough to generate statistically meaningful data on business outcomes.
Shorter pilots (under three weeks) don’t capture enough data to distinguish signal from noise, especially for use cases where business outcomes lag behind AI activity — like lead qualification, where the revenue impact shows up when leads close, not when they’re scored. Longer pilots (three to four months) generate more data but introduce a different risk: losing stakeholder attention. By month three, the executive sponsor has moved on, the team working on the pilot has been pulled to other priorities, and the pilot drifts into that twilight zone where it’s too expensive to kill and too poorly measured to champion.
The 30-day pilot isn’t about speed for its own sake. It’s about creating a forcing function — a defined moment where the organization must decide: scale, fix, or kill. That decision point is what separates pilots that generate value from pilots that generate costs.
Pre-Pilot: Setting Up for a Decision
The 30-day clock doesn’t start when the AI tool gets deployed. It starts when the measurement infrastructure is in place. Before the pilot begins, four things must be defined:
The business outcome KPI. Not “accuracy” or “adoption” — the business outcome that this AI initiative should change. Revenue influenced, costs reduced, time recovered, errors prevented. This is the metric that will appear in the scaling decision. If you can’t name it before the pilot starts, you’re not ready for the pilot. Our AI ROI framework provides a methodology for identifying the right success KPI by use case.
The baseline. What is the current performance on that KPI without AI? If the AI agent is supposed to reduce customer support resolution time, what’s the current average? If it’s supposed to improve lead conversion, what’s the current conversion rate? Without a baseline, there is no counterfactual, and without a counterfactual, there’s no way to attribute improvement to AI versus other factors.
The success threshold. How much improvement constitutes a “scale” decision? What range triggers a “fix” decision? What level triggers a “kill” decision? These thresholds must be agreed upon before the data comes in. Post-hoc threshold setting is subject to confirmation bias — teams will unconsciously set the bar wherever the data lands.
The decision authority. Who makes the scale/fix/kill call on day 30? If this isn’t defined upfront, the pilot’s data will be debated indefinitely by stakeholders with competing interests. The decision authority needs to be a single individual (typically the executive sponsor) with the organizational power to allocate or reallocate budget based on the results.
During the Pilot: What to Measure
Once the pilot is running, measurement operates on two tracks.
The outcome track measures the business KPI you defined pre-pilot. This is the number that matters for the scaling decision. Track it weekly so you can see trend direction, but don’t make decisions based on week-one data. Enterprise AI use cases need at least two to three weeks for patterns to stabilize, especially in workflows with downstream dependencies like sales pipeline or compliance review.
The diagnostic track measures operational and technical metrics that help you understand why the outcome KPI is moving (or not). If resolution time is dropping, the diagnostic track tells you whether that’s because the AI is providing better answers, because agents are spending less time searching for information, or because the easiest tickets are being routed to AI first. If the outcome KPI isn’t improving, the diagnostic track tells you where to look: data quality issues, workflow integration problems, user adoption gaps, or a fundamental mismatch between the AI capability and the business need.
McKinsey’s research is clear on the value of this approach: organizations that define and track AI-specific KPIs see nearly two-thirds meet or exceed their targets. The measurement itself doesn’t cause success — the discipline of defining what matters and instrumenting it creates organizational clarity that makes success more likely.
Day 30: The Decision Point
This is where most enterprises fail — not because they lack data, but because they lack a framework for using it. The day-30 decision uses four inputs:
Outcome KPI performance vs. threshold. Did the AI initiative hit the success threshold you defined pre-pilot? If yes, the data supports scaling. If it’s in the “fix” range, the diagnostic data tells you what to change. If it’s below the “kill” threshold, the data supports sunsetting the initiative and reallocating resources. The threshold was set before the data arrived, so this isn’t a subjective judgment. It’s a data-driven decision.
Cost-to-value ratio. What was the total cost of the pilot (tooling, infrastructure, team time, opportunity cost) versus the total value generated? Even at pilot scale, this ratio signals whether scaling will be financially viable. If the cost-to-value ratio is favorable at pilot scale, it typically improves at production scale due to economies.
Governance and risk profile. Can the AI initiative operate within your organization’s risk tolerance at production scale? Data security concerns, compliance requirements, and governance gaps that are manageable at pilot scale can become critical at production scale. If the governance profile isn’t ready for scaling, the decision might be “fix governance first, then scale.”
Operational readiness. Does the organization have the operational capacity to absorb the change at scale? User training, workflow integration, support infrastructure, and change management all need to be assessed. A pilot that works with 50 engaged early adopters may perform differently when deployed to 5,000 users with varying levels of enthusiasm and technical proficiency.
What Successful Enterprises Do Differently
The enterprises that escape pilot purgatory share three characteristics. First, they secure executive sponsorship with decision authority, not just endorsement. Organizations with top-level executive mandate scale AI three times faster and achieve significantly higher revenue impact compared to those stuck at pilot stage.
Second, they instrument measurement from day one, not after the pilot shows promising results. This means defining KPIs, establishing baselines, and deploying tracking before the AI tool goes live — not retrofitting measurement after the fact. Retrofitting measurement costs three to four times more than building it in from the start and produces lower-quality data because the baseline period is missing.
Third, they redesign workflows rather than just deploying tools. McKinsey found that AI high performers are 2.8 times more likely to redesign workflows (55% versus 20%) compared to other organizations. Dropping an AI tool into an existing workflow and measuring whether the workflow speeds up is the lowest-value form of AI measurement. Redesigning the workflow around AI capabilities and measuring the redesigned outcome is where the step-change improvements come from.
Breaking Free
Pilot purgatory isn’t a technology problem. It’s a measurement problem. The AI works. The organization just can’t prove it — because it never built the measurement infrastructure to generate decision-quality data in a defined timeframe.
The 30-day structured pilot is the DECIDE step in the SEE, MEASURE, DECIDE, ACT playbook. (This is the third of four companion deep-dives — see also SEE, MEASURE, and ACT.) It takes the visibility data from SEE and the business metrics from MEASURE and converts them into a concrete decision: scale, fix, or kill. No more indefinite experiments. No more “let’s give it another quarter.” No more pilot purgatory.
The enterprises moving from AI experimentation to business impact are the ones that commit to structured measurement before the pilot starts and structured decisions when the data comes in. The framework isn’t complicated. The discipline is what’s hard. And the cost of avoiding it — $15-25 million per year in wasted pilot investment — far exceeds the cost of getting it right.
Ready to run an AI pilot that actually produces a decision? Talk to an expert and we’ll show you how Olakai instruments AI measurement from day one — so your 30-day pilot generates the data your board needs to say yes.